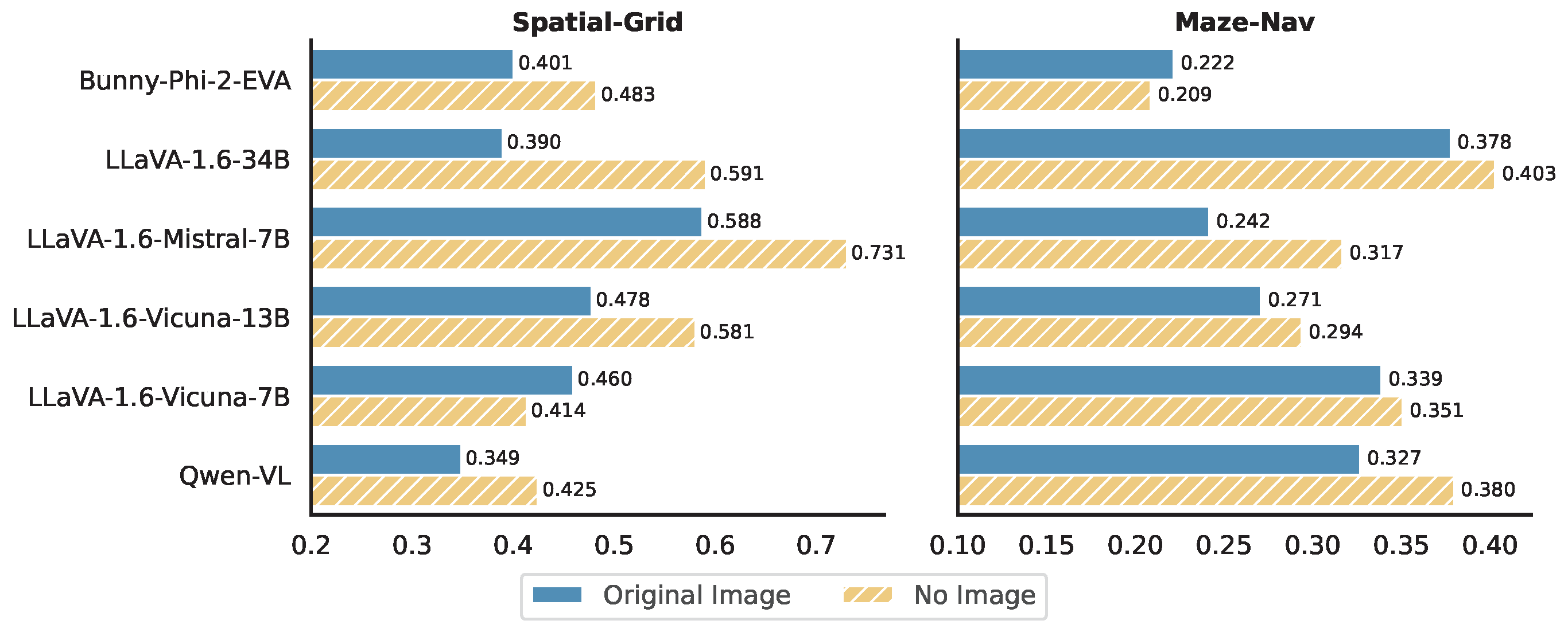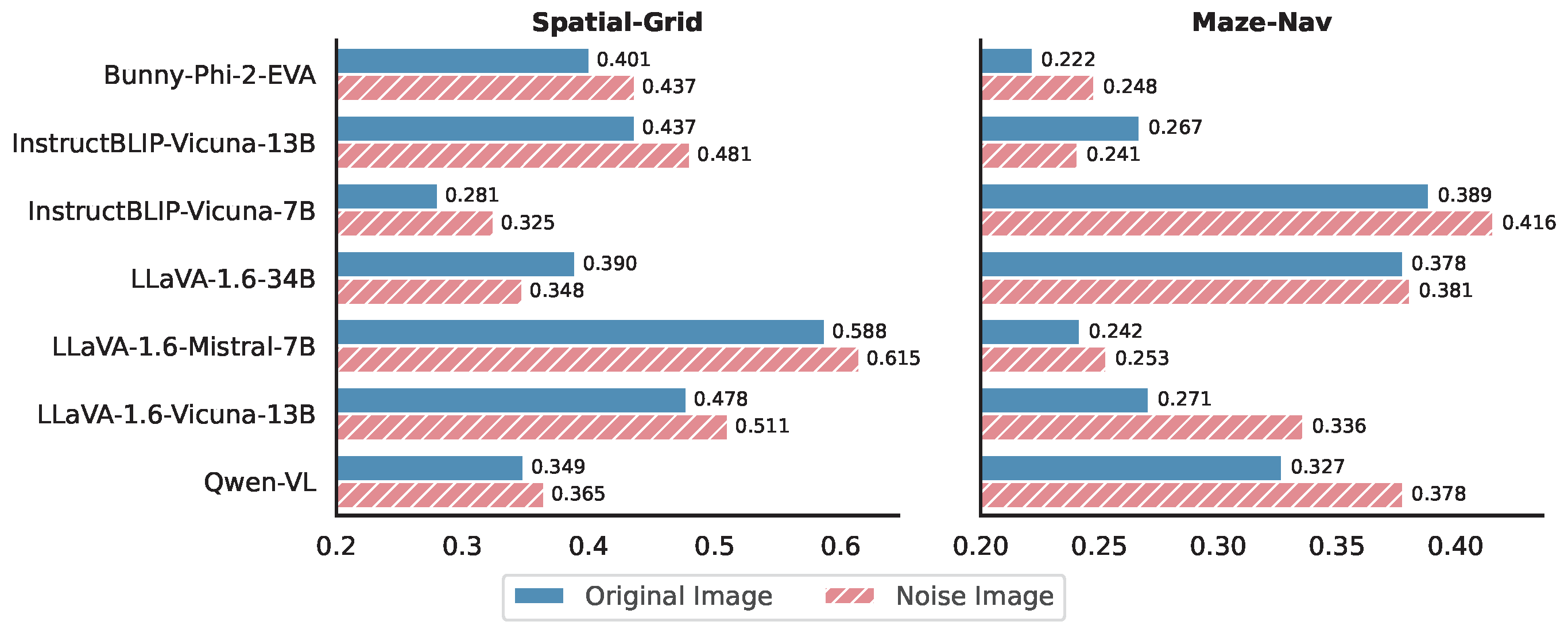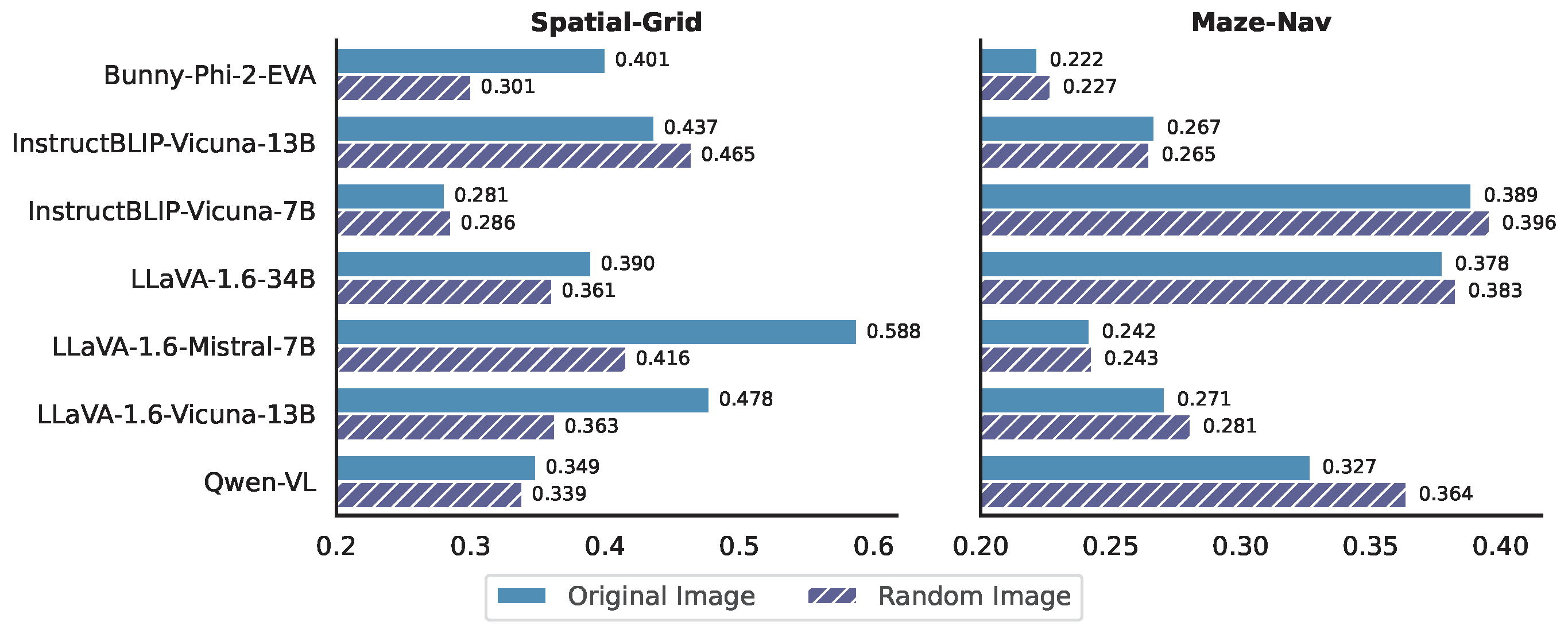

To better understand how VLMs process visual information, we conduct a series of controlled experiments in the VTQA (Vision-text input) setting. For each sample, we replace the original image input (that matches the textual description) with either: (1) No Image: only keep the textual input without the image input, (2) Noise Image: a Gaussian noise image irrelevant to the task, and (3) Random Image: a random image from the dataset that does not match the textual description.
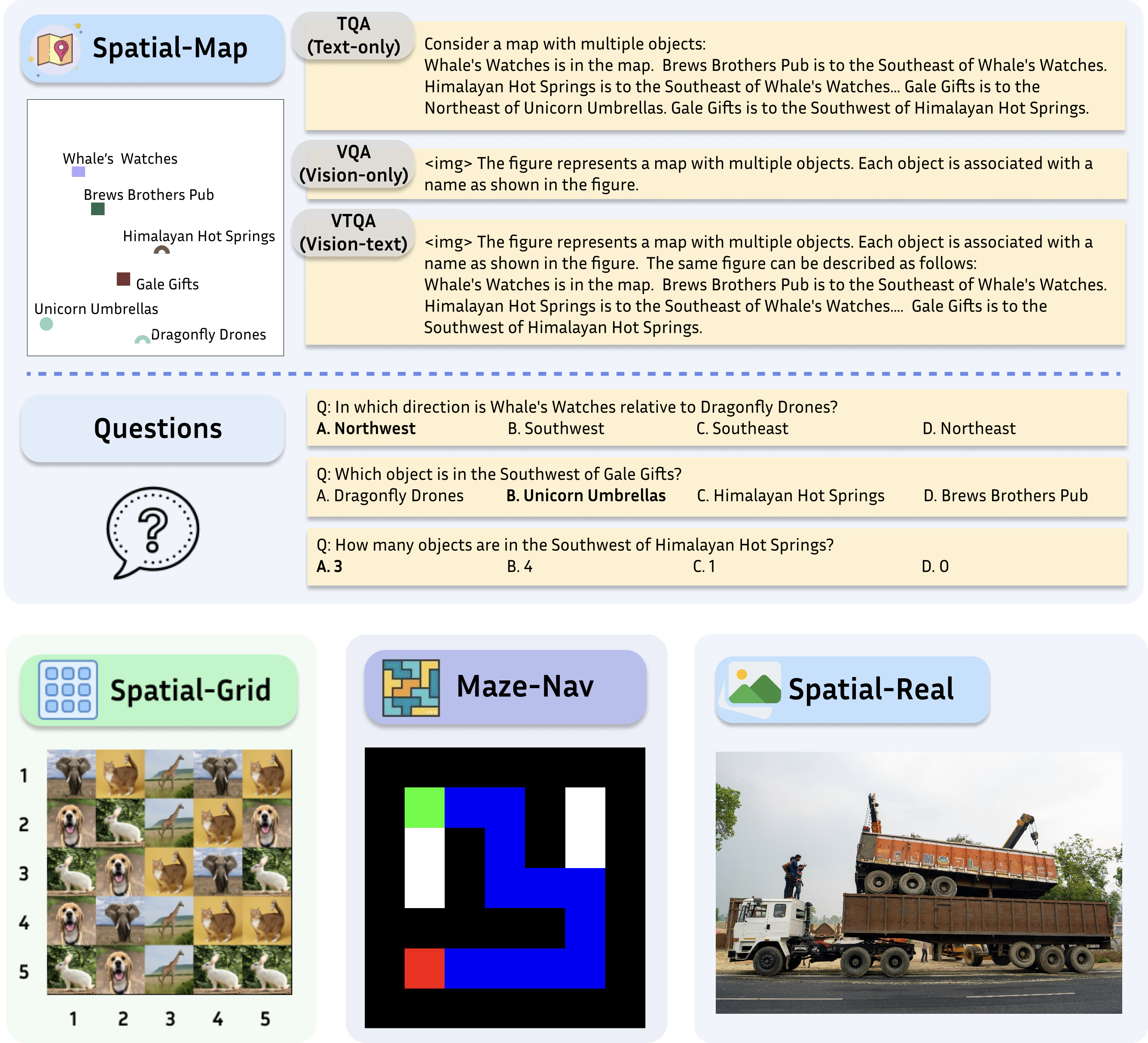
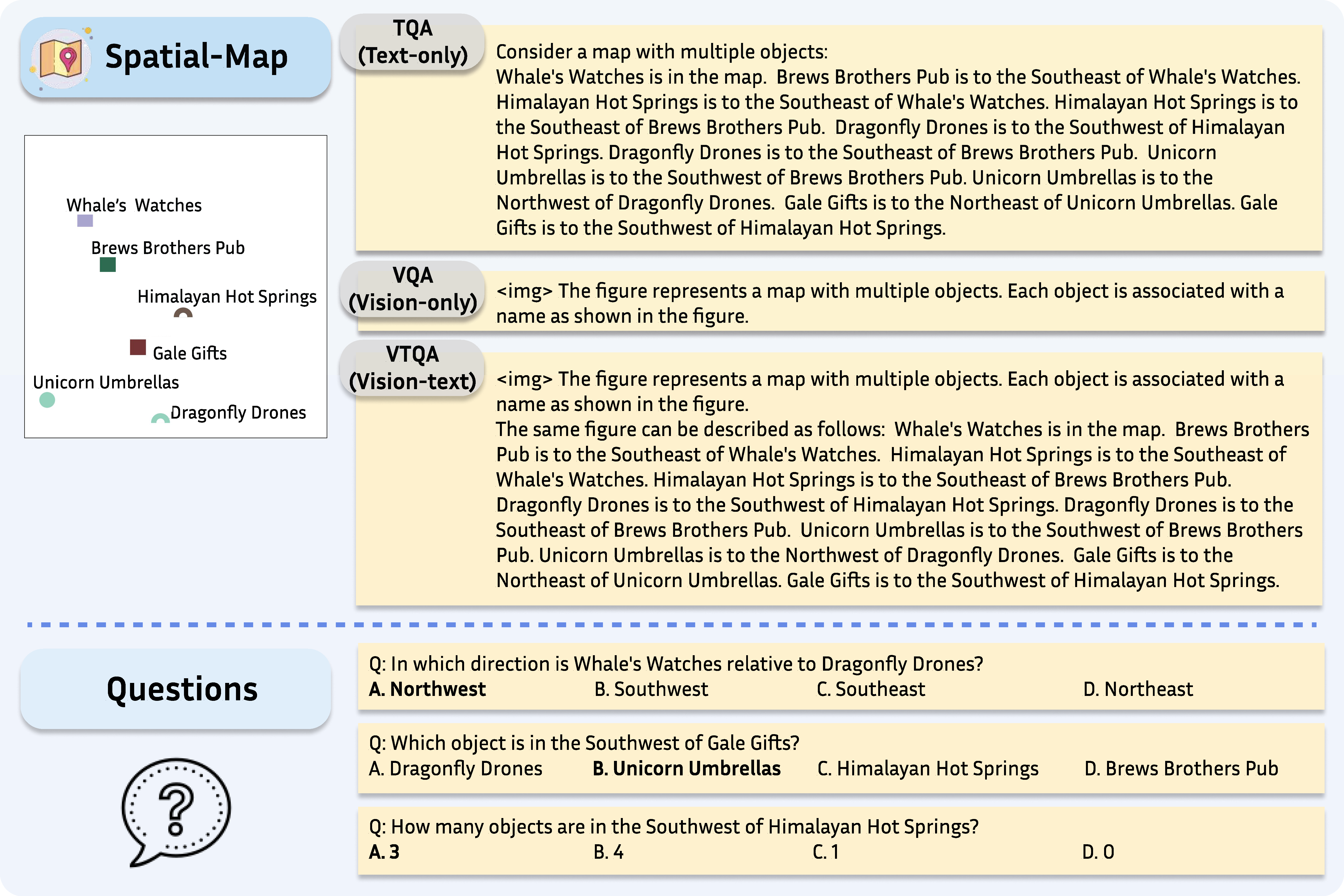
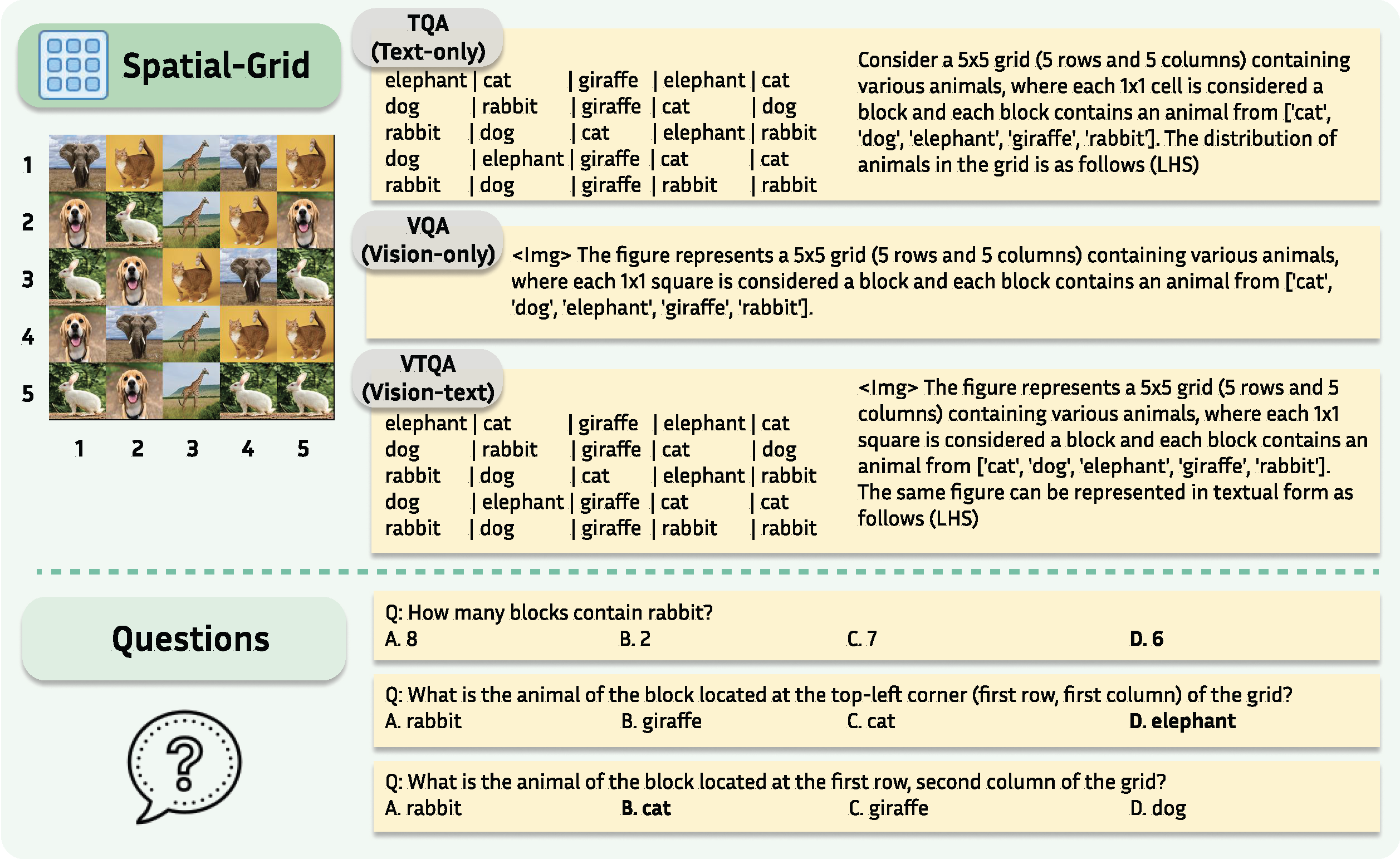
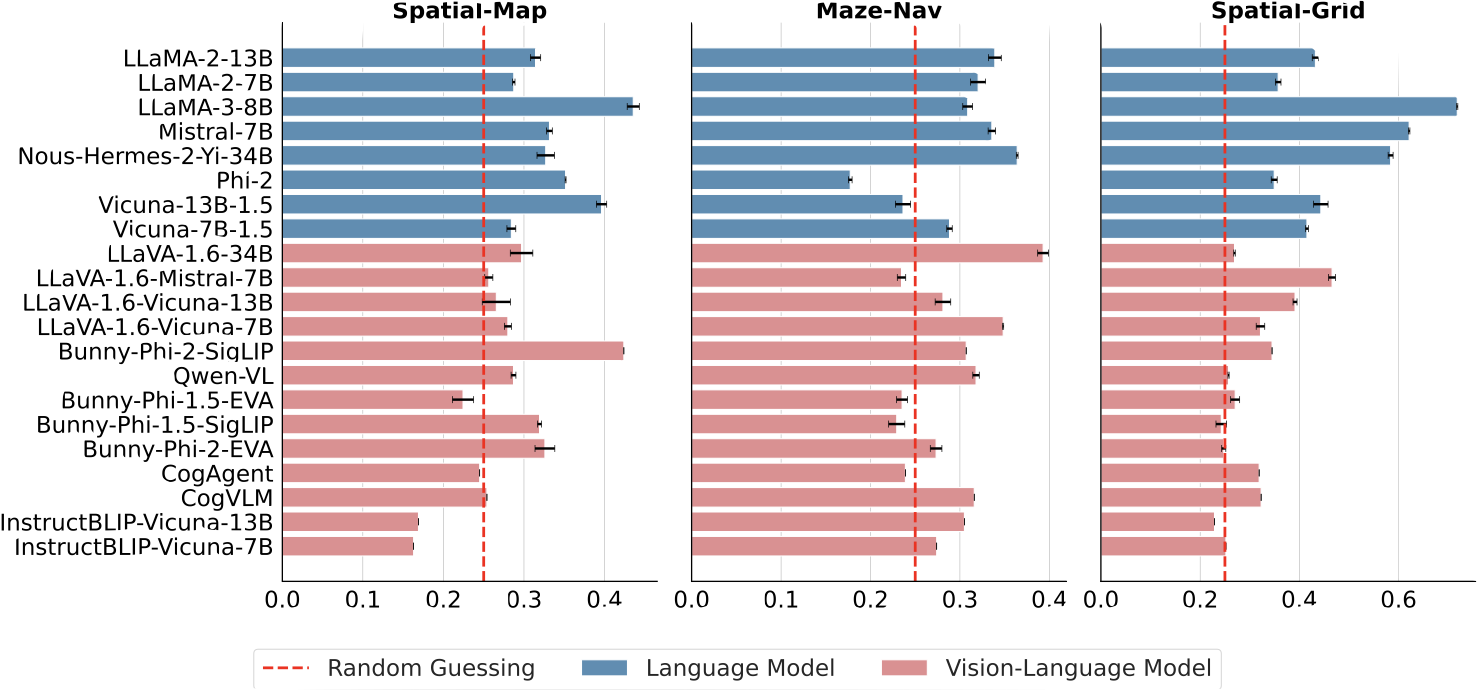
SpatialEval is a benchmark to evaluate spatial intelligence for LLMs and VLMs across four key dimensions: spatial relationships, positional understanding, object counting, and navigation. The benchmark comprises four distinct tasks: Spatial-Map for comprehending spatial relationships between objects in map-based scenarios; Maze-Nav for testing navigation through complex environments; Spatial-Grid for evaluating spatial reasoning within structured environments; and Spatial-Real for real-world spatial understanding tasks. Each task incorporates three input modalities: Text-only (TQA), Vision-only (VQA), and Vision-Text (VTQA) inputs.